Что data scientist может подсмотреть у разработчика
Содержание:
- Полный курс по Data Science
- С чего начать обучение Data Science самостоятельно
- Этап 3. Базовые понятия и классические алгоритмы машинного обучения
- Как лучше хранить данные, если вы дата-сайентист
- Подборка хороших курсов
- Специалист по изучению данных (data scientist)
- Что знает, умеет и сколько стоит Data Scientist
- Образование в области Data Science: ничего невозможного нет
- Проанализируем данные
- Чем отличается аналитик Big Data от исследователя данных
- 2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
- Что изучает Data Science
- FAQ
Полный курс по Data Science
Длительность: 18 месяцев, Около 8 часов в неделюФормат: занятия в записи, проверяют дз, есть общий чат и по выходным проводят вебинары с ответами на вопросыОсобенности: Школа специализируется на аналитике и разработке
Полная стоимость: 162 000₽/курс
Стоимость в рассрочку: от 4 500₽/месПрограмма курса
Ступеньки карьеры и перспективы
Профессия Data Scientist сама по себе является высоким достижением, для которой требуются серьёзные теоретические знания и практический опыт нескольких профессий. В любой организации такой специалист является ключевой фигурой. Чтобы достичь этой высоты надо упорно и целенаправленно работать и постоянно совершенствоваться во всех сферах, составляющих основу профессии.
Интересные факты о профессии
Про Data Scientist шутят: это универсал, который программирует лучше любого специалиста по статистике, и знает статистику лучше любого программиста. А в бизнес-процессах разбирается лучше руководителя компании.
ЧТО ТАКОЕ «BIGDATA» в реальных цифрах?
- Через каждые 2 дня объём данных увеличивается на такое количество информации, которое было создано человечеством от Рождества Христова до 2003 г.
- 90% всех существующих на сегодня данных появились за последние 2 года.
- До 2020 г. объём информации увеличится от 3,2 до 40 зеттабайт. 1 зеттабайт = 10 21 байт.
- В течение 1 минуты в сети Facebook загружается 200 тысяч фото, отправляется 205 млн. писем, выставляется 1,8 млн. лайков.
- В течение 1 секунды Google обрабатывает 40 тыс. поисковых запросов.
- Каждые 1,2 года удваивается общий объём данных в каждой отрасли.
- К 2020 г. объём рынка Hadoop-сервисов вырастет до $50 млрд.
- В США в 2015 г. создано 1,9 млн. рабочих мест для специалистов, работающих на проектах Big Data.
- Технологии Big Data увеличивают прибыль торговых сетей на 60% в год.
- По прогнозам объём рынка Big Data увеличится до $68,7 млрд. в 2020 г. по сравнению с $28,5 млрд. в 2014 г.
Несмотря на такие позитивные показатели роста, бывают и ошибки в прогнозах. Так, например, одна из самых громких ошибок 2016 года: не сбылись прогнозы по поводу выборов президента США. Прогнозы были представлены знаменитыми Data Scientist США Нейт Сильвером, Керк Борном и Биллом Шмарзо в пользу Хиллари Клинтон. В прошлые предвыборные компании они давали точные прогнозы и ни разу не ошибались.
В этом году Нейт Сильвер, например, дал точный прогноз для 41 штата, но для 9 штатов — ошибся, что и привело к победе Трампа. Проанализировав причины ошибок 2016 года, они пришли к выводу, что:
- Математические модели объективно отражают картину в момент их создания. Но они имеют период полураспада, к концу которого ситуация может кардинально измениться. Прогнозные качества модели со временем ухудшаются. В данном случае, например, сыграли свою роль должностные преступления, неравенство доходов и другие социальные потрясения. Поэтому модель необходимо регулярно корректировать с учётом новых данных. Это не было сделано.
- Необходимо искать и учитывать дополнительные данные, которые могут оказать существенное влияние на прогнозы. Так, при просмотре видео митингов в предвыборной кампании Клинтон и Трампа, не было учтено общее количество участников митингов. Речь шла приблизительно о сотнях человек. Оказалось, что в пользу Трампа на митинге присутствовало 400-600 человек в каждом, а в пользу Клинтон — всего 150-200, что и отразилось на результатах.
- Математические модели в предвыборных кампаниях основаны на демографических данных: возраст, раса, пол, доходы, статус в обществе и т.п. Вес каждой группы определяется тем, как они голосовали на прошлых выборах. Такой прогноз имеет погрешность 3-4 % и работает достоверно при большом разрыве между кандидатами. Но в данном случае разрыв между Клинтон и Трампом был небольшим, и эта погрешность оказала существенное влияние на результаты выборов.
- Не было учтено иррациональное поведение людей. Проведенные опросы общественного мнения создают иллюзию, что люди проголосуют так, как ответили в опросах. Но иногда они поступают противоположным образом. В данном случае следовало бы дополнительно провести аналитику лица и речи, чтобы выявить недобросовестное отношение к голосованию.
В целом, ошибочный прогноз оказался таковым по причине небольшого разрыва между кандидатами. В случае большого разрыва эти погрешности не имели бы такого решающего значения.
С чего начать обучение Data Science самостоятельно
Научиться основам Data Science с нуля можно примерно за год. Для этого нужно освоить несколько направлений.
Python. Из-за простого синтаксиса этот язык идеально подходит для новичков. Со знанием Python можно работать и в других IT-областях, например веб-разработке и даже гейм-дизайне. Для работы нужно также освоить инструменты Data Science, например Scikit-Learn, которые упрощают написание кода на Python.
Математика. Со знанием Python уже можно работать ML-инженером. Но для полного цикла Data Science нужно уметь работать с математическими моделями, чтобы анализировать данные. Для этого изучают линейную алгебру, матанализ, статистику и теорию вероятностей. Также математика нужна, чтобы понимать, как устроен алгоритм, и уметь подобрать правильные параметры для задачи.
Машинное обучение. Используйте знания Python и математики для создания и тренировки ML-моделей. Код для моделей и наборы данных для обучения (датасеты) можно найти, например, на сайте Kaggle. Подробнее о том, зачем дата-сайентисту Kaggle, читайте в статье.
Визуальный анализ данных (EDA) отвечает на вопросы о том, что происходит внутри данных, позволяет найти выбросы в них и получить инсайты про создание уникальных фичей для будущего алгоритма.
Вот несколько полезных ссылок для новичков:
Книги:
«Изучаем Python», Марк Лутц.
«Python и машинное обучение. Машинное и глубокое обучение с использованием Python, scikit-learn и TensorFlow», Себастьян Рашка, Вахид Мирджалили.
«Теория вероятностей и математическая статистика», Н. Ш. Кремер.
«Курс математического анализа» Л. Д. Кудрявцев.
«Линейная алгебра», В. А. Ильин, Э. Г. Позняк.
Курсы:
Питонтьютор — бесплатный практический курс Python в браузере.
Бесплатный курс по Python от Mail.ru и МФТИ на Coursera.
Модуль по визуализации данных из курса Mail.ru и МФТИ.
Фреймворки, модели и датасеты
Основные библиотеки: NumPy, Scipy, Pandas.
Библиотеки для машинного и глубокого обучения: Scikit-Learn, TensorFlow, Theano, Keras.
Инструменты визуализации: Matplotlib и Seaborn.
Статья на хабре со ссылками на модели из разных сфер бизнеса на GitHub.
Список нужных фреймворков, библиотек, книг и курсов по машинному обучению на GitHub.
Kaggle — база моделей и датасетов, открытые соревнования дата-сайентистов и курсы по машинному обучению.
Дата-сайентистом можно стать и без опыта в этой сфере. За 13 месяцев на курсе по Data Science вы изучите основы программирования и анализа данных на Python, научитесь выгружать нужные данные с помощью SQL и делать анализ данных с помощью библиотек Pandas и NumPy, разберетесь в основах машинного обучения. После обучения у вас будет 8 проектов для портфолио.
Курс
Data Science с нуля
Станьте востребованным специалистом на рынке IT! За 13 месяцев вы получите набор компетенций, необходимый для уровня Junior.
- структуры данных Python для проектирования алгоритмов;
- как получать данные из веб-источников или по API;
- методы матанализа, линейной алгебры, статистики и теории вероятности для обработки данных;
- и многое другое.
Узнать больше
Промокод “BLOG10” +5% скидки
Этап 3. Базовые понятия и классические алгоритмы машинного обучения
(Этот этап может занять 200-400 ч в зависимости от того, насколько хорошо изначально вы владеете математикой)
Базовые понятия машинного обучения:
-
Кросс-валидация
-
Overfitting
-
Регуляризация
-
Data leakage
-
Экстраполяции (понимание возможности в контексте разных алгоритмов)
Базовые алгоритмы, которые достаточно знать на уровне главных принципов:
-
Прогнозирование и классификация:
-
Линейная регрессия
-
Дерево решений
-
Логистическая регрессия
-
Random forest
-
Градиентный бустинг
-
kNN
-
-
Кластерзиация: k-means
-
Работа с временными рядами: экспоненциальное сглаживание
-
Понижение размерности: PCA
Базовые приёмы подготовки данных: dummy переменные, one-hot encoding, tf-idf
Математика:
-
умение считать вероятности: основы комбинаторики, вероятности независимых событий и условные вероятности (формула Байеса).
-
Понимать смысл фразы: «correlation does not imply causation», чтобы верно трактовать результаты моделей.
-
Мат.методы, необходимые для полного понимания, как работают ключевые модели машинного обучения: Градиентный спуск. Максимальное правдоподобие (max likelihood), понимание зачем на практике используются логарифмы (log-likelihood). Понимание как строиться целевая функция логистической регрессии (зачем log в log-odds), понимание сути логистической функции (часто называемой «сигмоид»). С одной стороны, нет жесткой необходимости всё это понять на данном этапе, т.к все алгоритмы можно использовать как черные ящики, зная только основные принципы. Но понимание математики поможет глубже понять разные модели и придать уверенности в их использовании. Позднее, для уровня senior, эти знания являются уже обязательным:
Без практических навыков знания данного этапа мало повышают ваши шансы на трудоустройство. Но значительно облегчают общение с другими дата-сайентистами и открывают путь для понимания многих дальнейших источников (книг/курсов) и позволяют начать практиковаться в их использовании.
Как лучше хранить данные, если вы дата-сайентист
Обычно Аркадий работает с небольшими датасетами и хранит их в файлах от 50 до 100 Мб. Но с новым проектом к нему пришел большой набор данных, и Аркадий решил как обычно сложить его в csv-файл, который получился объемом 13 Гб. И здесь начинаются проблемы.
Такой файл сложно передать кому-то из коллег: вы будете очень долго ждать, пока он загрузится в Slack или Google Drive. А еще он может вообще не открыться на компьютере. Или формат такого файла плохо доходит до прода: объем данных растет с каждым днем и файл разрастается.
Что же можно с этим сделать? Посмотрим, как хранят файлы разработчики.
-
Они используют базы данных, оптимизированные под свои задачи и под тот объем данных, который у них есть.
-
Валидируют форматы данных при загрузке.
-
Поддерживают отказоустойчивость сервисов и баз данных, которые к ним подключены.
-
Заранее думают о возможностях масштабирования. То есть сразу прогнозируют, насколько объем данных вырастет через год, и нужно ли будет переделывать архитектуру с нуля, или у них будет возможность масштабироваться до нужного объема.
Конечно, дата-сайентистам не всегда нужно делать отказоустойчивые сервисы, но тем не менее, они могут подсмотреть некоторые штуки, которые облегчат работу.
Мы уже поняли, что сохранять все в csv-формате — не вариант. Такой файл не влезет в RAM среднестатистического компьютера, а скорость чтения явно превысит 2 минуты. В этом случае нет никакой оптимизации, валидации форматов, отказоустойчивости и масштабируемости.

Попробуем разделить этот файл по отдельным партициям. Например, найти колонку с маленькой вариативностью данных, по которой можно разделить их и сложить в отдельные файлы. После этого мы сможем обрабатывать отдельные файлы под необходимые задачи. Так мы решаем проблему масштабируемости, но размер файлов все равно остается большим.
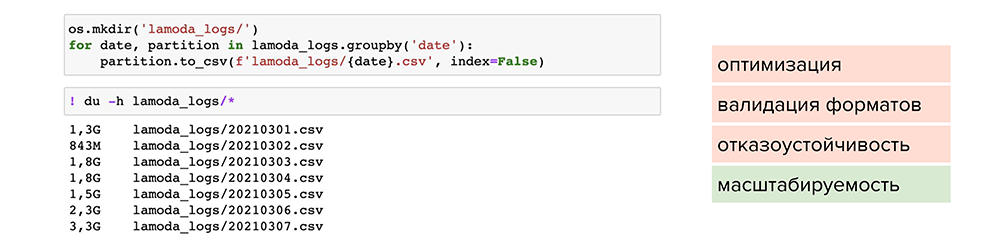
Теперь попробуем сжать файлы. Например, можно воспользоваться обычной утилитой сжатия для одного файла gzip. Она доступна в pandas, нужно лишь при сохранении указать ее в параметре , и файл станет весить 1,2 Гб вместо 13 Гб. Но читается он также 2 минуты. Делаем вывод, что такой способ мало подходит для оптимизации, хотя масштабируемость присутствует — файлы стали занимать меньше места на диске.
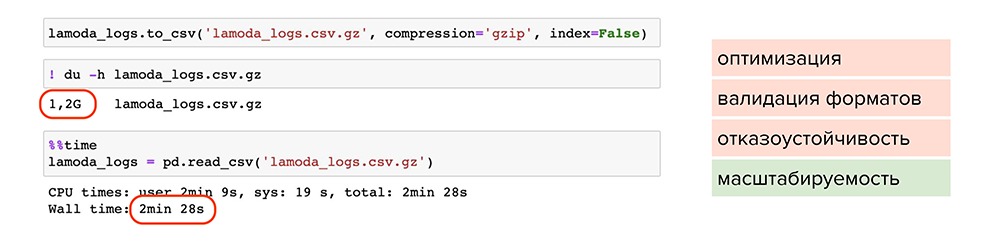
Попробуем улучшить результат. Например, можно использовать parquet — это специальный формат сжатия или, более умными словами, партиционированная бинарная колоночная сериализация для табличных данных. Он позволит работать с каждым типом данных в каждой колонке отдельно: например, сжимать числовые данные одним способом, текстовые или строковые данные — другим способом, и таким образом оптимизировать как хранение информации, так и чтение.
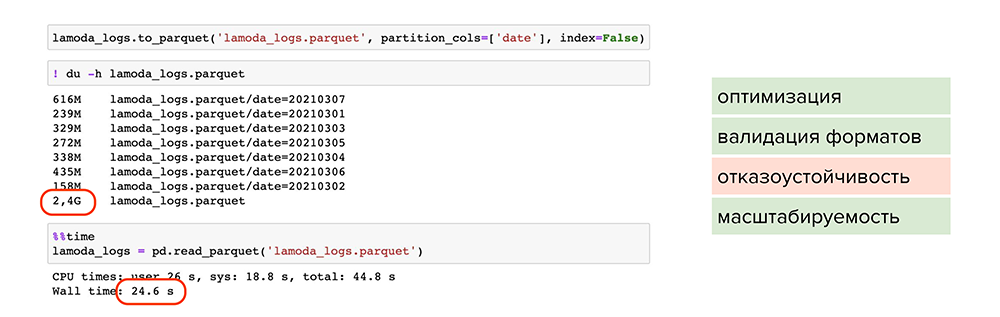
С применением parquet:
-
Большой объем данных стал весить 2,4 Гб и читаться за 24 секунды. Файлы оптимально сжаты, поделены на партиции и у каждого есть метаданные.
-
Происходит валидация форматов, поскольку parquet работает с каждым форматом колонки отдельно и проверяет их при записи. Вероятность записать ошибочные данные снижается.
-
Присутствует масштабируемость, поскольку мы пишем данные в разные партиции и сжимаем их.
Однако мы не победили один пункт — отказоустойчивость.
Чтобы покрыть все пункты, можно обратиться к специальным фреймворкам и базам данных. Например, подойдут ClickHouse или Hadoop, особенно, если это продакшн-решения или повторяющиеся истории.
Подборка хороших курсов
- Практический курс по машинному обучению с менторской поддержкой
- Курс содержит полный обзор современных методов машинного обучения от простых моделей до работы с нейросетями и Big Data от опытного практика области
- Специализация Яндекса и МФТИ на Coursera на русском языке
- Полное введение в data science и машинное обучение на базе Python
- Теорию можно смотреть бесплатно, задания и сертификат — платные
- Интерактивное пошаговое изучение Data Science с фокусом на Python
- Обучение через практику: с самого начала работа с реальными данными и кодом
- 3 направления на выбор: Data Scientist, Data Analyst или Data Engineer
- Интерактивный онлайн-курс по Data Science с фокусом на R
- 66 курсов по машинному обучению, анализу данных и статистике
- Курс построен на решении практических задач
«Специализация Аналитик Данных»
- Специализация включает сквозной курс и тренажёры по инструментам для анализа данных.
- Срок обучения: 6 месяцев
- Онлайн-программа профессиональной переподготовки от Института биоинформатики и Санкт-Петербургского Академического университета РАН, не требующая специальной подготовки
- Срок обучения: 1 год. С лета 2017 — ускоренная программа (полгода)
- Стоимость: 1999 рублей в месяц
Курс по математике для Data Science
Курс содержит много практики, которая не ограничивается решением классических уравнений и абстрактных заданий.
Основы статистики
Бесплатное и ясное введение в математическую статистику для всех
- Легендарный курс основателя Coursera и одного из лучших специалистов по искусственному интеллекту Эндрю Ын (Andrew Ng)
- Этот курс можно считать индустриальным стандартом по введению в машинное обучение
- Добрый человек “перевел” задания на Python (в оригинале нужно все делать на Octave)
- Курс от NVIDIA и SkillFactrory
- Комплексный курс по глубокому обучению на Python для начинающих
- Видеозаписи занятий легендарной Школы анализа данных Яндекса
- Курсы: машинное обучение, алгоритмы и структуры данных, параллельные вычисления, дискретный анализ и теория вероятности и др.
“10 онлайн-курсов по машинному обучению”
Подборка удаленных образовательных программ, составленная проектом “Теплица социальных технологий”
- Любопытное введение в статистику на примере … котиков
- Вы получите знания об основах описательной статистики, дисперсионном и корреляционном анализе
- Фишка курса — наглядность (опять же картинки с котиками)
- Учит извлекать данные из разных файлов, баз данных и API
- Преобразовывать данные для удобного анализа
- Интерпретировать и визуализировать результаты анализа
Курс по Python для анализа данных
Практический курс по Python для аналитиков с менторской поддержкой.
- Курс от Высшей школы экономики
- Онлайн-курс по самому популярному языку программирования для data scientist’ов
Специалист по изучению данных (data scientist)
Основная статья — здесь
Почему Data Scientist сексуальнее, чем BI-аналитик
В связи с ростом популярности data science (DS) возникает два совершенно очевидных вопроса. Первый – в чем состоит качественное отличие этого недавно сформировавшегося научного направления от существующего несколько десятков лет и активно используемого в индустрии направления business intelligence (BI)? Второй — возможно более важный с практической точки зрения — чем различаются функции специалистов двух родственных специальностей data scientist и BI analyst? В материале, подготовленном специально для TAdviser, на эти вопросы отвечает журналист Леонид Черняк.
Что знает, умеет и сколько стоит Data Scientist
Специалисты в области Data Science называются учеными или исследователями по данным (Data Scientist’ами). В настоящее время это одна из самых востребованных и высокооплачиваемых ИТ-профессий. Например, в Москве на январь 2020 года месячный труд ученого по данным оценивается около 200 тысяч рублей (от 70 до 250 т.р.). В США оплата выше – $110 – $140 тысяч в год .
Основная практическая цель работы ученого по данным – это извлечение полезных для бизнеса сведений из больших массивов информации, выявление закономерностей, разработка и проверка гипотез путем моделирования и разработки нового программного обеспечения .
Для достижения этой цели Data Scientist использует следующие инструменты:
- пакеты статистического моделирования (R-Studio, Matlab);
- технологии больших данных (Apache Hadoop, HDFS, Spark, Kafka), NoSQL-СУБД (Cassandra, HBase, MongoDB, DynamoDB и прочие нереляционные решения);
- SQL для работы с классическими реляционными базами данных и формирования структурированных запросов к NoSQL-решениям с помощью Apache Phoenix, Drill, Impala, Hive и пр.
- языки программирования (Python, R, Java, Scala) для разработки моделей машинного обучения и прототипов программного обеспечения;
- информационные системы класса Business Intelligence (дэшборды, витрины данных) для визуализации бизнес-показателей из информационных массивов.
Таким образом, можно сделать вывод, что Data Science включает следующие области знаний:
- математика: математический анализ, матстатистика и матлогика;
- информатика: разработка программного обеспечения, баз данных, моделей и алгоритмов машинного обучения (нейросети, байесовские алгоритмы, регрессионные ряды и пр.), Data Mining;
- системный анализ (методы анализа предметной области, Business Intelligence).
Подробнее о профессии Data Scientist’a и его отличиях от инженера и аналитика данных (Data Engineer и Data Analyst) мы писали здесь.

Портрет профессиональных компетенций ученого по данным
Источники
- https://ru.wikipedia.org/wiki/Наука_о_данных
- https://www.profguide.io/professions/data_scientist.html
- https://chernobrovov.ru/articles/analitika-dannyh-i-data-science-shodstva-i-razlichiya.html
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.
Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Проанализируем данные
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример – любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
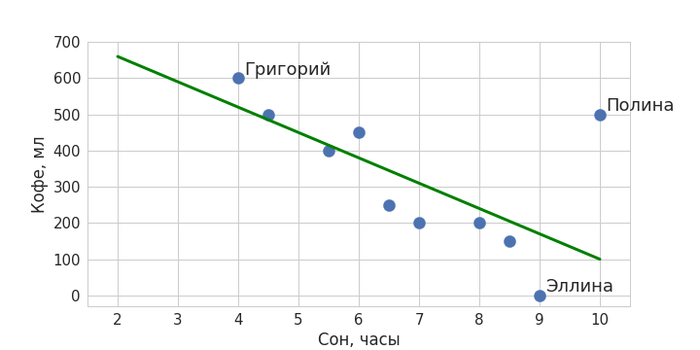
Зеленая линия – и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель – ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
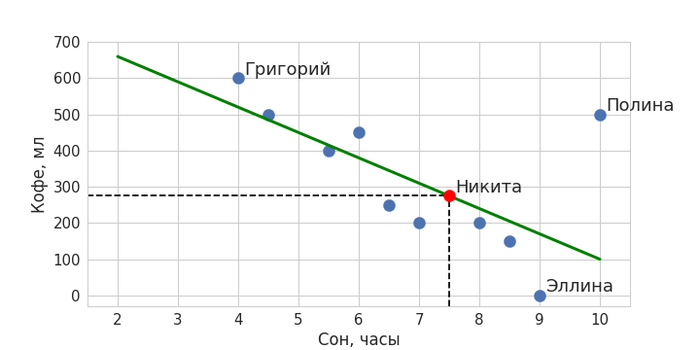
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Чем отличается аналитик Big Data от исследователя данных
На первый взгляд может показаться, что Data Scientist ничем не отличается от Data Analyst, ведь их рабочие обязанности и профессиональные компетенции частично пересекаются. Однако, это не совсем взаимозаменяемые специальности. При значительном сходстве, отличия между ними также весьма существенные:
- по инструментарию – аналитик чаще всего работает с ETL-хранилищами и витринами данных, тогда как исследователь взаимодействует с Big Data системами хранения и обработки информации (стек Apache Hadoop, NoSQL-базы данных и т.д.), а также статистическими пакетами (R-studio, Matlab и пр.);
- по методам исследований – Data Analyst чаще использует методы системного анализа и бизнес-аналитики, тогда как Data Scientist, в основном, работает с математическими средствами Computer Science (модели и алгоритмы машинного обучения, а также другие разделы искусственного интеллекта);
- по зарплате – на рынке труда Data Scientist стоит чуть выше, чем Data Analyst (100-200 т.р. против 80-150 т.р., по данным рекрутингового портала HeadHunter в августе 2019 г.). Возможно, это связано с более высоким порогом входа в профессию: исследователь по данным обладает навыками программирования, тогда как Data Analyst, в основном, работает с уже готовыми SQL/ETL-средствами.
На практике в некоторых компаниях всю работу по данным, включая бизнес-аналитику и построение моделей Machine Learning выполняет один и тот же человек. Однако, в связи с популярностью T-модели компетенций ИТ-специалиста, при наличии широкого круга профессиональных знаний и умений предполагается экспертная концентрация в узкой предметной области. Поэтому сегодня все больше компаний стремятся разделять обязанности Data Analyst и Data Scientist, а также инженера по данным (Data Engineer) и администратора Big Data, о чем мы расскажем в следующих статьях.
Data Scientist – одна из самых востребованных профессий на современном ИТ-рынке
В области Big Data ученому по данным пригодятся практические знания по облачным вычислениям и инструментам машинного обучения. Эти и другие вопросы по исследованию данных мы рассматриваем на наших курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- PYML: Машинное обучение на Python
- DPREP: Подготовка данных для Data Mining
- DSML: Машинное обучение в R
- DSAV: Анализ данных и визуализация в R
- AZURE: Машинное обучение на Microsoft Azure
Смотреть расписание
Записаться на курс
2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
НИУ ВШЭ первым из российских университетов начнет формировать компетенции по Data Science у всех студентов, обучающихся на программах бакалавриата. В рамках проекта Data Culture расширится набор дисциплин и появятся образовательные треки по анализу больших данных.
Data Culture – это общий термин для обозначения навыков и культуры работы с данными. Высшая школа экономики считает, что запуск проекта, направленного на воспитание у студентов таких навыков, сейчас актуален из-за огромного потенциала использования больших данных и трансформации профессий, которые, так или иначе, используют или могут использовать большие массивы информации. Потребность рынка в специалистах с компетенциями по анализу данных, перерастает в необходимость воспитания во всех предметных областях профессионалов, понимающих возможности и ограничения массивов данных, потенциал и особенности методов машинного обучения, а в ряде направлений и умеющих пользоваться этими технологиями и инструментами.
Проект Data Culture станет продолжением интеграции в образовательные программы НИУ ВШЭ элементов, направленных на воспитание у студентов культуры и умений работы с данными. Он расширит возможности студентов уже абсолютно всех образовательных программ по формированию компетенций, связанных с Data Science. Это позволит выпускникам в перспективе быстро и эффективно интегрироваться в решение профессиональных задач на стыке предметных областей и компьютерных технологий, которые сегодня являются передовыми, но уже в ближайшей перспективе станут привычной практикой.
Проект включает разработку отдельных курсов по Data Science так или иначе кастомизированных под специфику образовательных программ, а также формирование специализированных образовательных треков из таких курсов с разной степенью сложности: начального, базового, продвинутого, профессионального и экспертного уровней. Это связано с большим разнообразием образовательных программ, студенты которых дифференцированы по базовым компетенциям в сфере математики и информатики. Для программ или их блоков будет предложена система курсов Data Culture в определенной вилке «сквозного уровня продвинутости». Более того, эти системы курсов определятся спецификой предметных областей.
Внедрение дисциплин Data Culture будет происходить поэтапно. В 2017/2018 учебном году будут включены в учебные планы обязательные и элективные курсы по направлению Data Science для части образовательных программ, но таковых будет более половины. Например, у студентов-гуманитариев, юристов и дизайнеров появится вводный курс по цифровой грамотности, программы экономистов дополнятся дисциплиной по машинному обучению, политологов – анализу социальных сетей, у статистиков появится курс по программированию и извлечению и анализу интернет-данных. С 2018 года к проекту примкнут все образовательные программы.
Для реализации проекта Data Culture предполагается привлечение преподавательского состава как из академической среды (преподаватели факультета компьютерных наук, сотрудники департамента математики факультета экономических наук и общеуниверситетской кафедры высшей математики и т.д.), так и из индустрии (участники сообществ по анализу данных, участники тематических мероприятий по анализу данных, проводимых в IT-компаниях). Более того, преподаватели факультетов, которые уже погружены в работу с данными в рамках своей профессиональной деятельности, также будут разрабатывать курсы в рамках проекта Data Culture для студентов своих и смежных факультетов.
Что изучает Data Science
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
Data Science (DS) — междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
В 2010-х годах объемы данных по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).
Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах)
(Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.
FAQ
Стоит ли идти в профессию, не имея никакой предварительной подготовки?
Если у вас нет навыков в программировании, а математику знаете на уровне школьной программы – освоить профессию будет сложно. Прежде чем решиться на полноценный курс, советуем обязательно пройти бесплатные вводные уроки, которые рассказывают о специфике профессии, знакомят с базой. Так вы сможете понять общую планку, и сможете ли вы до нее дотянутся.
В каких сферах работает дата сайентист?
Сейчас большинство вакансий в нашей стране предлагают ИТ-компании, но в целом эта профессия может использоваться практически в любой индустрии: медицине, технологическом производстве, торговых сетях, финансовых учреждениях – любой достаточно крупной компании.
Как правильно выстраивать учебу в дата сайнс самостоятельно?
Самому выстроить комплексную подготовку довольно сложно, но возможно. Мы рекомендуем ориентироваться на советы Ребекки Викери, которая сама освоила профессию и успешно работает в ней уже 10 лет. Для начала изучите язык Python и его возможности в анализе данных, следующий шаг – машинное обучение, затем SQL, язык R, разработка программного обеспечения, глубокое обучение. Уже после этого стоит потратить время на изучение теории и математики
На что стоит обратить внимание?
Обязательно – Derivatives, то есть производные, Geometric definition, Calculating the derivative of a function, Nonlinear functions, Chain rule, Composite functions, Composite function derivatives, Multiple functions, градиенты, theory of probability (теория вероятности)
Не менее важно прокачать знания в линейной алгебре. Начните с изучения матриц, которые используются во многих популярных инструментах машинного обучения, например, XGBOOST
Сюда же – векторные пространства и линейные уравнения, матричные преобразования (Matrix transformations), умножение матриц — Matrix multiplication. После этого, стоит уделить время изучению статистики и приступать к практике.