Что такое big data engineering, и как развиваться в этой сфере
Содержание:
- Big data — простыми словами
- Перспективы использования Биг Дата
- Какие тренды обсуждает сообщество
- The big benefits of big data analytics
- Каким должен быть специалист по большим данным
- Чем конкретно занимается аналитик данных
- Какие профессии есть в сфере больших данных
- Как стать Data Engineer и куда расти
- Что должен знать и уметь аналитик данных
- Почему современным предприятиям нужны фабрики данных
- Different Types of Big Data Analytics
- Как данные становятся большими
- Что такое Big data?
- Структура специализации
- Какие специализации бывают у аналитика данных?
- Кто такой Big data engineer
- Manufacturing and Natural Resources
- Рынок технологий больших данных в России и мире
- Как устроены фабрики данных: Big Data и не только
- Conclusion
Big data — простыми словами
В современном мире Big data — социально-экономический феномен, который связан с тем, что появились новые технологические возможности для анализа огромного количества данных.
Для простоты понимания представьте супермаркет, в котором все товары лежат не в привычном вам порядке. Хлеб рядом с фруктами, томатная паста около замороженной пиццы, жидкость для розжига напротив стеллажа с тампонами, на котором помимо прочих стоит авокадо, тофу или грибы шиитаке. Big data расставляют всё по своим местам и помогают вам найти ореховое молоко, узнать стоимость и срок годности, а еще — кто, кроме вас, покупает такое молоко и чем оно лучше молока коровьего.
Кеннет Кукьер: Большие данные — лучшие данные
Перспективы использования Биг Дата
Blockchain и Big Data — две развивающиеся и взаимодополняющие друг друга технологии. С 2016 блокчейн часто обсуждается в СМИ. Это криптографически безопасная технология распределенных баз данных для хранения и передачи информации. Защита частной и конфиденциальной информации — актуальная и будущая проблема больших данных, которую способен решить блокчейн.
Почти каждая отрасль начала инвестировать в аналитику Big Data, но некоторые инвестируют больше, чем другие. По информации IDC, больше тратят на банковские услуги, дискретное производство, процессное производство и профессиональные услуги. По исследованиям Wikibon, выручка от продаж программ и услуг на мировом рынке в 2018 году составила $42 млрд, а в 2027 году преодолеет отметку в $100 млрд.
По оценкам Neimeth, блокчейн составит до 20% общего рынка больших данных к 2030 году, принося до $100 млрд. годового дохода. Это превосходит прибыль PayPal, Visa и Mastercard вместе взятые.
Аналитика Big Data будет важна для отслеживания транзакций и позволит компаниям, использующим блокчейн, выявлять скрытые схемы и выяснять с кем они взаимодействуют в блокчейне.
Какие тренды обсуждает сообщество
Постепенно набирает силу еще одно направление, которое может привести к бурному росту количества данных — Интернет вещей (IoT). Большие данные такого рода поступают с датчиков устройств, объединенных в сеть, причем количество датчиков в начале следующего десятилетия должно достигнуть десятков миллиардов.
Устройства самые разные — от бытовых приборов до транспортных средств и промышленных станков, непрерывный поток информации от которых потребует дополнительной инфраструктуры и большого числа высококвалифицированных специалистов. Это означает, что в ближайшее время возникнет острый дефицит дата инженеров и аналитиков больших данных.
Освоить востребованную профессию в Аналитике больших данных можно всего за полтора года на курсах GeekBrains.
The big benefits of big data analytics
The ability to analyze more data at a faster rate can provide big benefits to an organization, allowing it to more efficiently use data to answer important questions. Big data analytics is important because it lets organizations use colossal amounts of data in multiple formats from multiple sources to identify opportunities and risks, helping organizations move quickly and improve their bottom lines. Some benefits of big data analytics include:
- Cost savings. Helping organizations identify ways to do business more efficiently
- Product development. Providing a better understanding of customer needs
- Market insights. Tracking purchase behavior and market trends
Read more about how real organizations reap the benefits of big data.
Каким должен быть специалист по большим данным
Поскольку данные расположены на кластере серверов, для их обработки используется более сложная инфраструктура. Это оказывает большую нагрузку на человека, который с ней работает — система должна быть очень надежной.
Сделать надежным один сервер легко. Но когда их несколько — вероятность падения возрастает пропорционально количеству, и так же растет и ответственность дата-инженера, который с этими данными работает.
Аналитик big data должен понимать, что он всегда может получить неполные или даже неправильные данные. Он написал программу, доверился ее результатам, а потом узнал, что из-за падения одного сервера из тысячи часть данных была отключена, и все выводы неверны.
Взять, к примеру, текстовый поиск. Допустим все слова расположены в алфавитном порядке на нескольких серверах (если говорить очень просто и условно). И вот отключился один из них, пропали все слова на букву «К». Поиск перестал выдавать слово «Кино». Следом пропадают все киноновости, и аналитик делает ложный вывод, что людей больше не интересуют кинотеатры.
Поэтому специалист по большим данным должен знать принципы работы от самых нижних уровней — серверов, экосистем, планировщиков задач — до самых верхнеуровневых программ — библиотек машинного обучения, статистического анализа и прочего. Он должен понимать принципы работы железа, компьютерного оборудования и всего, что настроено поверх него.
В остальном нужно знать все то же, что и при работе с малыми данным. Нужна математика, нужно уметь программировать и особенно хорошо знать алгоритмы распределенных вычислений, уметь приложить их к обычным принципам работы с данными и машинного обучения.
Чем конкретно занимается аналитик данных
Основной обязанностью аналитика данных считается извлечение из Big data (больших массивов информации) сведений, которые являются наиболее значимыми для принятия лучших решений в плане эффективного управления бизнесом. В большинстве случаев аналитик big data самостоятельно обрабатывает информационные массивы. Для этого ему приходится выполнять ряд необходимых операций:
- собирать данные;
- готовить сведения к анализу (делать выборку, чистить и сортировать);
- находить закономерности в наборах информации;
- визуализировать данные для скорости восприятия и понимания готовых результатов и будущих направлений развития;
- формулировать предположения относительно повышения эффективности отдельных бизнес-метрик путем изменения других параметров.
Какие профессии есть в сфере больших данных
Две основные профессии — это аналитики и дата-инженеры.
Аналитик прежде всего работает с информацией. Его интересуют табличные данные, он занимается моделями. В его обязанности входит агрегация, очистка, дополнение и визуализация данных. То есть, аналитик в биг дата — это связующее звено между информацией в сыром виде и бизнесом.
У аналитика есть два основных направления работы. Первое — он может преобразовывать полученную информацию, делать выводы и представлять ее в понятном виде.
Второе — аналитики разрабатывают приложения, которые будет работать и выдавать результат автоматически. Например, делать прогноз по рынку ценных бумаг каждый день.
Дата инженер — это более низкоуровневая специальность. Это человек, который должен обеспечить хранение, обработку и доставку информации аналитику. Но там, где идет поставка и очистка — их обязанности могут пересекаться
Bigdata-инженеру достается вся черная работа. Если отказали системы, или из кластера пропал один из серверов — подключается он. Это очень ответственная и стрессовая работа. Система может отключиться и в выходные, и в нерабочее время, и инженер должен оперативно предпринять меры.
Это две основные профессии, но есть и другие. Они появляются, когда к задачам, связанным с искусственным интеллектом, добавляются алгоритмы параллельных вычислений. Например, NLP-инженер. Это программист, который занимается обработкой естественного языка, особенно в случаях, когда надо не просто найти слова, а уловить смысл текста. Такие инженеры пишут программы для чат-ботов и диалоговых систем, голосовых помощников и автоматизированных колл-центров.
Есть ситуации, когда надо проклассифицировать миллиарды картинок, сделать модерацию, отсеять лишнее и найти похожее. Эти профессии больше пересекаются с компьютерным зрением.
Как стать Data Engineer и куда расти
Профессия дата-инженера довольно требовательна к бэкграунду. Костяк профессии составляют разработчики на Python и Scala, которые решили уйти в Big Data. В русскоговорящих странах, к примеру, процент использования этих языков в работе с большими данными примерно 50/50. Если знаете Java — тоже хорошо.
Хорошее знание SQL тоже важно. Поэтому в Data Engineer часто попадают специалисты, которые уже ранее работали с данными: Data Analyst, Business Analyst, Data Scientist
Дата-сайентисту с опытом от 1–2 лет будет проще всего войти в специальность.
Фреймворками можно овладевать в процессе работы, но хотя бы несколько важно знать на хорошем уровне уже в самом начале.
Дальнейшее развитие для специалистов Big Data Engineers тоже довольно разнообразное. Можно уйти в смежные Data Science или Data Analytics, в архитектуру данных, Devops-специальности. Можно также уйти в чистую разработку на Python или Scala, но так делает довольно малый процент спецов.
Перспективы у профессии просто колоссальные. Согласно данным Dice Tech Job Report 2020, Data Engineering показывает невероятные темпы роста — в 2019 году рынок профессии увеличился на 50 %. Для сравнения: стандартным ростом считается 3–5 %.
В 2020 году темпы замедлились, но всё равно они многократно опережают другие отрасли. Спрос на специальность вырос ещё на 24,8 %. И подобные темпы сохранятся еще на протяжении минимум пяти лет.
Так что сейчас как раз просто шикарный момент, чтобы войти в профессию Data Engineering с нашим курсом Data Engineering и стать востребованным специалистом в любом серьёзном Data Science проекте. Пока рынок растёт настолько быстро, то возможность найти хорошую работу, есть даже у новичков.
Узнайте, как прокачаться и в других областях работы с данными или освоить их с нуля:
Что должен знать и уметь аналитик данных
Такой специалист формулирует гипотезы, проводит статистические тесты на существующих данных для решения текущих вопросов, на которые нет ответа.
Минимальный набор скиллов начинающего аналитика:
- Работать в Google-таблицах, группировать, фильтровать данные — на ходу, без перекладывания из таблички в табличку.
- Уметь писать SQL-запросы.
- Изучить минимум один язык программирования: Python или R.
- Делать выводы и представлять результаты в виде интерактивных дашбордов (Tableau, Power BI).
- Разбираться в бизнес-процессах и понимать ключевые метрики анализа эффективности.
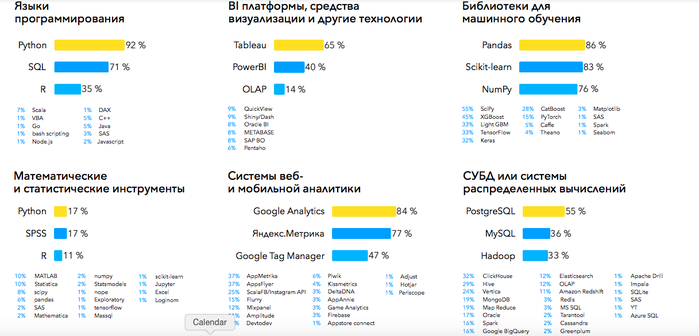
Инструменты, которые используют аналитики
Основные навыки аналитика данных:
- Сбор и анализ требований заказчиков к отчетности.
- Получение данных с помощью языка запросов SQL.
- Применение в работе ключевых математических методов и основ статистики.
- Очистка и трансформация данных с помощью Python.
- Прогнозирование событий на основе данных.
- Анализ результатов кампаний, исследований и тестирования продуктовых гипотез.
- Способность создавать аналитические решения и представлять их бизнесу
А еще хорошие аналитики данных умеют работать с Big Data, проверять гипотезы с помощью подходов А/Б-тестирования и быть настоящими исследователями.
Большинство работодателей просят посчитать определенные метрики, например, какие товары чаще всего возвращают покупатели. Иногда нужно рассчитать инвестиционный потенциал и скорректировать бизнес-модель.
Почему современным предприятиям нужны фабрики данных
Концепция Data Fabric возникла благодаря активному использованию больших данных в условиях типовых ограничений традиционных процессов управления информацией. В частности, корпоративные Data Lakes на базе Apache Hadoop отлично справляются с хранением множества разрозненных и разноформатных данных. Но эту информацию не просто искать, анализировать и интегрировать с другими датасетами. Это усложняет аналитику больших данных, снижая ценность информации. В свою очередь, интерактивная аналитика и когнитивные вычисления, в т.ч. с помощью методов Machine Learning, требуют высокой скорости доступа к информации, хранящейся в Data Lake. Таким образом, можно сказать, что основными драйверами развития концепции Data Fabric стали потребности в быстрой аналитике Big Data и необходимость распространения BI-подхода на все информационные активы предприятия .
Кроме того, для организации, управляемой данными (data-driven) особенно актуальны вопросы обеспечения информационной безопасности. В этом контексте Data Fabric будет обеспечивать защиту данных, реализуя согласованное управление с помощью унифицированных API и настраиваемого доступа к ресурсам. Также фабрика данных направлена на поддержку гибкости в прозрачных процессах обновления, аудита, интеграции, маршрутизации и трансформации данных для конкретных бизнес-целей .
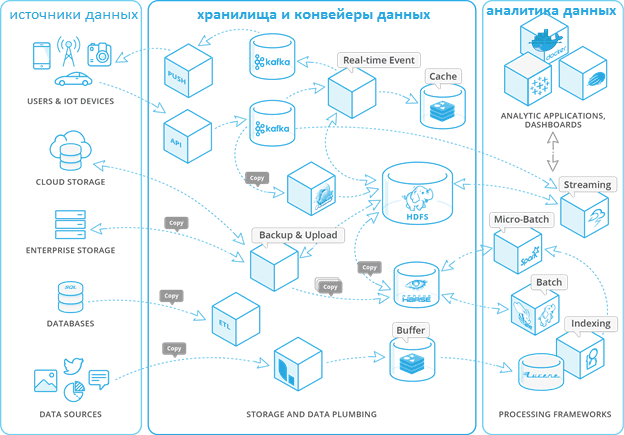
Компоненты фабрики данных
Different Types of Big Data Analytics
Here are the four types of Big Data analytics:
1. Descriptive Analytics
This summarizes past data into a form that people can easily read. This helps in creating reports, like a company’s revenue, profit, sales, and so on. Also, it helps in the tabulation of social media metrics. Use Case: The Dow Chemical Company analyzed its past data to increase facility utilization across its office and lab space. Using descriptive analytics, Dow was able to identify underutilized space. This space consolidation helped the company save nearly US $4 million annually.
2. Diagnostic Analytics
This is done to understand what caused a problem in the first place. Techniques like drill-down, data mining, and data recovery are all examples. Organizations use diagnostic analytics because they provide an in-depth insight into a particular problem.Use Case: An e-commerce company’s report shows that their sales have gone down, although customers are adding products to their carts. This can be due to various reasons like the form didn’t load correctly, the shipping fee is too high, or there are not enough payment options available. This is where you can use diagnostic analytics to find the reason.
3. Predictive Analytics
This type of analytics looks into the historical and present data to make predictions of the future. Predictive analytics uses data mining, AI, and machine learning to analyze current data and make predictions about the future. It works on predicting customer trends, market trends, and so on.Use Case: PayPal determines what kind of precautions they have to take to protect their clients against fraudulent transactions. Using predictive analytics, the company uses all the historical payment data and user behavior data and builds an algorithm that predicts fraudulent activities.
Как данные становятся большими
Крупные операторы данных — телеком- и интернет-компании, банки — могут многое рассказать о своих клиентах. Им известен пол и возраст пользователей, доход и траты, потребительские предпочтения, модели телефонов, продолжительность разговоров, ежедневные маршруты и многое другое.
Более того, компании обычно не ограничиваются собственными данными. Помимо информации, которую бизнес получает в процессе основной деятельности, он использует внешние источники.
Например, мы работаем с источниками данных о географических объектах, которые позволяют определить их тип — магазин, жилой дом, школа, вуз, стадион и так далее. Для этого применяются разные ресурсы — от визуального осмотра до спутниковых снимков. В качестве внешних источников мы используем в том числе картографические сервисы (такие как 2ГИС или Open Street Map), данные дистанционного зондирования (Роскосмос, «Терратех»), статистические материалы Росстата и Росреестра, специально организованные полевые исследования и опросы.

Принять как данные: как бизнес учится извлекать прибыль из big data
В общей сложности размер кластера с данными Tele2 составляет около 10 петабайт (10 млн гигабайт). Но сырые данные — это промежуточный этап. Чтобы превратить имеющийся массив в Big Data, информацию нужно обработать, наложить одни данные на другие. И в итоге — трансформировать их в аналитические и математические модели, позволяющие понимать и предсказывать события и тренды.
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Структура специализации
В 2020 году аналитика Big Data используется в более чем 55% компаний по всему миру. При этом рост объемов рынка решений в Центральной и Восточной Европе ежегодно увеличивается на 11%, и в 2022 году составит 5,4 млрд. долл.
Есть две основные специализации Big Data:
- Инженеры – отвечают за хранение, преобразование информации и быстрый доступ к ней.
- Аналитики – отвечают за анализ большого количества информации, выявление взаимосвязей и построение моделей.
Чтобы стать профессионалом своего дела, в целом требуется овладеть следующими знаниями:
Программирование
Важно знать как минимум два языка программирования (чем больше, тем лучше), поскольку кодирование является основой для проведения численного и статистического анализа больших массивов данных. Наиболее популярны R, Python, Ruby, C++, Java, Scala и Julia.
Количественные способности
Необходимо обладать твердыми знаниями статистики и математики, включая линейную алгебру, многомерное исчисление, распределение вероятностей, проверку гипотез, байесовский анализ, анализ временных рядов и продольный анализ.
Вычислительные инструменты. Работа аналитика Big Data универсальна. Пользователь должен чувствовать себя комфортно при работе с различными инструментами и вычислительными фреймворками, включая базовые (Excel и SQL) и продвинутые (Hadoop, MapReduce, Spark, Storm, SPSS, Cognos, SAS и MATLAB). Эти технологии помогают в обработке больших данных, которые можно передавать в потоковом режиме.
Хранение данных. Каждый аналитик должен обладать навыками работы с реляционными и нереляционными системами БД, такими как MySQL, Oracle, DB2, NoSQL, HDFS, MongoDB, CouchDB, Cassandra.
Деловая хватка. Какой толк в выводах аналитиков, если они не могут визуализировать их с точки зрения бизнеса? Чтобы использовать полученные знания на практике, нужно иметь понимание делового мира. Только тогда можно определить потенциальные возможности для бизнеса и использовать полученные результаты для принятия наиболее эффективных решений.
Коммуникативные навыки. Необходимо знать, как эффективно передавать и представлять свои выводы для облегчения понимания другими специалистами – то есть обладать безупречными навыками письменной и устной коммуникации, чтобы объяснить свое видение другим и разложить сложные идеи на более простые термины.
Знание английского языка на уровне чтения технической документации.
Навык машинного обучения.
Также очень важно основательно знать отрасль, в которой происходит работа. Постоянно обучаясь и развиваясь, специалист по Big Data может пройти следующий карьерный путь:
Постоянно обучаясь и развиваясь, специалист по Big Data может пройти следующий карьерный путь:
- Стажер.
- Младший аналитик.
- Аналитик.
- Старший аналитик.
- Руководитель отдела.
- Директор управления по анализу.
Какие специализации бывают у аналитика данных?
В профессии аналитик данных есть классическое для IT деление на джуниор-, мидл- и синьор-аналитиков. Но, имея базовые знания по работе с данными, можно применять их в других направлениях. Вот несколько специализаций.
Продуктовый аналитик нужен, если необходимо развивать продукт на основе метрик и анализа данных. Продуктовый аналитик глубоко погружается в тематику, проводит тесты и исследования, чтобы понять, какие функции пользуются популярностью, а какие — нет, какие проблемы возникают у пользователей при использовании продукта.
Маркетинговый аналитик помогает привлечь клиентов через рекламу, оптимизировать затраты, опираясь на анализ данных по пользовательскому поведению и кликам.
BI-аналитик проектирует системы для анализа и хранения данных, тестирует гипотезы и автоматизирует отчетность. Он помогает бизнесу моделировать различные ситуации, делать правильные выводы и распределять ресурсы между отделами.
Кто такой Big data engineer
Задачи, которые выполняет инженер больших данных, входят в цикл разработки машинного обучения. Его работа тесно связана с аналитикой данных и data science.
Главная задача Data engineer — построить систему хранения данных, очистить и отформатировать их, а также настроить процесс обновления и приёма данных для дальнейшей работы с ними. Помимо этого, инженер данных занимается непосредственным созданием моделей обработки информации и машинного обучения.
Инженер данных востребован в самых разных сферах: e-commerce, финансах, туризме, строительстве — в любом бизнесе, где есть поток разнообразных данных и потребность их анализировать.
С технической стороны, наиболее частыми задачами инженера данных можно считать:
Разработка процессов конвейерной обработки данных. Это одна из основных задач BDE в любом проекте. Именно создание структуры процессов обработки и их реализация в контексте конкретной задачи. Эти процессы позволяют с максимальной эффективностью осуществлять ETL (extract, transform, load) — изъятие данных, их трансформирование и загрузку в другую систему для последующей обработки. В статичных и потоковых данных эти процессы значительно различаются. Для этого чаще всего используются фреймворки Kafka, Apache Spark, Storm, Flink, а также облачные сервисы Google Cloud и Azure.
Хранение данных. Разработка механизма хранения и доступа к данным — еще одна частая задача дата-инженеров. Нужно подобрать наиболее соответствующий тип баз данных — реляционные или нереляционные, а затем настроить сами процессы.
Обработка данных. Процессы структурирования, изменения типа, очищения данных и поиска аномалий во всех этих алгоритмах. Предварительная обработка может быть частью либо системы машинного обучения, либо системы конвейерной обработки данных.
Разработка инфраструктуры данных. Дата-инженер принимает участие в развёртывании и настройке существующих решений, определении необходимых ресурсных мощностей для программ и систем, построении систем сбора метрик и логов.
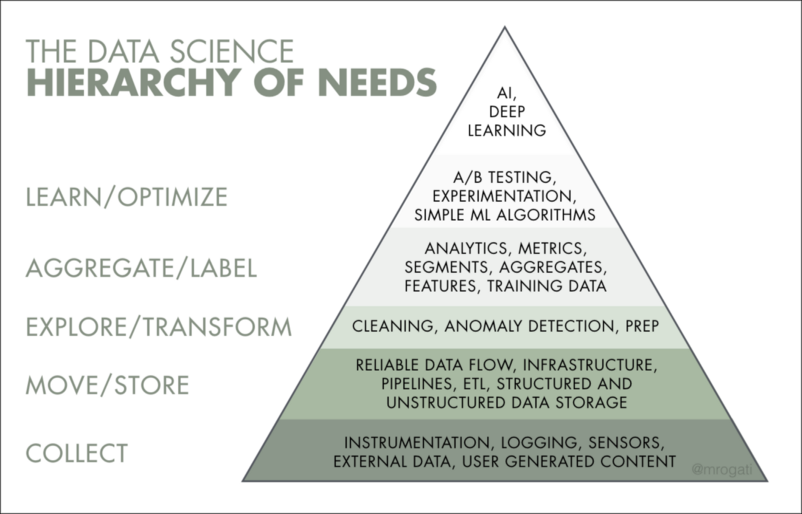
В иерархии работы над данными инженер отвечает за три нижние ступеньки: сбор, обработку и трансформацию данных.
Manufacturing and Natural Resources
Industry-specific Big Data Challenges
Increasing demand for natural resources, including oil, agricultural products, minerals, gas, metals, and so on, has led to an increase in the volume, complexity, and velocity of data that is a challenge to handle.
Similarly, large volumes of data from the manufacturing industry are untapped. The underutilization of this information prevents the improved quality of products, energy efficiency, reliability, and better profit margins.
Applications of Big Data in Manufacturing and Natural Resources
In the natural resources industry, Big Data allows for predictive modeling to support decision making that has been utilized for ingesting and integrating large amounts of data from geospatial data, graphical data, text, and temporal data. Areas of interest where this has been used include; seismic interpretation and reservoir characterization.
Big data has also been used in solving today’s manufacturing challenges and to gain a competitive advantage, among other benefits.
In the graphic below, a study by Deloitte shows the use of supply chain capabilities from Big Data currently in use and their expected use in the future.
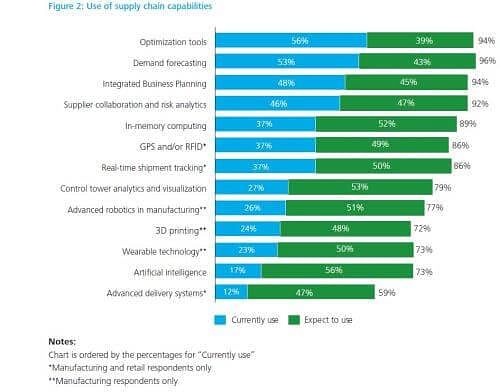
Source: Supply Chain Talent of the Future
Big Data Providers in this industry include CSC, Aspen Technology, Invensys, and Pentaho.
Рынок технологий больших данных в России и мире
По данным на 2014 год 40% объема рынка больших данных составляют сервисные услуги. Немного уступает (38%) данному показателю выручка от использования Big Data в компьютерном оборудовании. Оставшиеся 22% приходятся на долю программного обеспечения.
Наиболее полезные в мировом сегменте продукты для решения проблем Big Data, согласно статистическим данным, – аналитические платформы In-memory и NoSQL . 15 и 12 процентов рынка соответственно занимают аналитическое ПО Log-file и платформы Columnar. А вот Hadoop/MapReduce на практике справляются с проблемами больших данных не слишком эффективно.
Результаты внедрения технологий больших данных:
- рост качества клиентского сервиса;
- оптимизация интеграции в цепи поставок;
- оптимизация планирования организации;
- ускорение взаимодействия с клиентами;
- повышение эффективности обработки запросов клиентов;
- снижение затрат на сервис;
- оптимизация обработки клиентских заявок.
Как устроены фабрики данных: Big Data и не только
На текущий момент фабрика данных – это тренд в области Big Data и корпоративного ИТ-сектора, а не готовые технологические решения. На практике сегодня для сквозной интеграции и ETL/ELT-процессов используется вся мощь технологий Big Data: Apache Kafka, Spark, Hadoop, Hive, NiFi, AirFlow и прочие средства для сбора, обработки, маршрутизации и преобразования пакетных и потоковых данных в различных форматах.
Помимо упомянутых и других инструментов Big Data, а также базовых положений DataOps, концепция Data Fabric еще дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей . Примечательно, что графовую аналитику Gartner также относит к наиболее перспективным трендам 2020 года .
Наконец, фабрика данных по максимуму использует весь потенциал облачных технологий, виртуализируя все компоненты ИТ-инфраструктуры, от наборов информации до программных приложений . Подобная сервисная модель соответствует DevOps-подходу, а потому инструменты контейнеризации (Docker, Kubernetes) также относятся к средствам Data Fabric.
Таким образом, для развертывания уникальной фабрики данных, а также создания непрерывных конвейеров автоматического сбора и обработки информационных пакетов и потоков необходимы совместные усилия всех профильных ИТ-специалистов по большим данным. Потребуется целая команда администраторов Data Lakes, локальных и облачных кластеров, разработчиков распределенных приложений, инженеров и аналитиков данных, а также специалистов по методам Machine Learning.
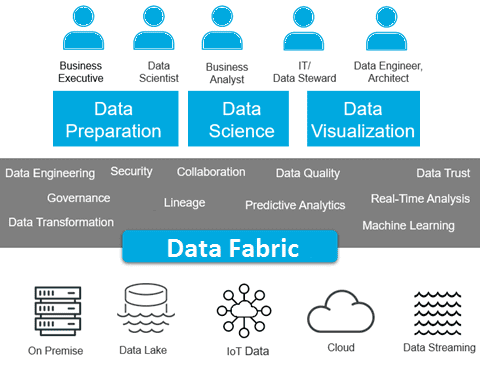
Пользователи и ключевые черты фабрики больших данных
Подробнее о том, как организовать собственную Data Fabric для цифровизации своих бизнес-процессов и аналитики больших данных, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Аналитика больших данных для руководителей
Смотреть расписание
Записаться на курс
Источники
- https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends/
- https://docs.microsoft.com/ru-ru/azure/data-factory/frequently-asked-questions
- https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
- https://hightech.plus/2018/11/26/kak-rabotayut-kitaiskie-fabriki-dannih-gde-treniruyut-ii
- https://www.computerweekly.com/blog/Data-Matters/The-Enterprise-Data-Fabric-an-information-architecture-for-our-times
- https://tdwi.org/articles/2018/06/20/ta-all-data-fabrics-for-big-data.aspx
- https://www.itweek.ru/bigdata/article/detail.php?ID=210273
- https://blog.cloudera.com/conquering-hybrid-and-multi-cloud-with-big-data-fabric/
Conclusion
In this write-up Data Science vs. Big Data vs. Data Analytics, we discussed minor and major differences between Data Science vs. Big Data vs. Data Analytics such as definition, application, skills, and salary-related to the specific position.
Are you planning to take a course on Data Science, Big Data, or Data Analytics? I suggest you check out the Simplilearn course.
The course has in-depth technical content on Data Science, Big Data, and Data Analytics.
If you have any questions related to this article Data Science vs. Big Data vs. Data Analytics, please drop your queries in the comments section below.